-
Handling Daylight Saving Time in Cron Jobs
- Our business is located in Maine (same timezone as New York; we set clocks back one hour in the Fall and ahead one hour in the Spring)
- Server A uses ET (automatically adjusts to UTC-4 in the summer, and UTC-5 in the winter)
- Server B uses UTC (not affected by Daylight Saving Time) – we cannot control the timezone of this server
We want to ensure both servers are always referencing, figuratively, the same clock on the wall in Maine.
Here’s what we can do to make sure the timing of cron jobs on Server B (UTC) match the changing times of Server A (ET).
12345# Every day at 11:55pm EST (due to conditional, commands only run during Standard Time (fall/winter)55 4 * * * [ `TZ=America/New_York date +\%Z` = EST ] && php artisan scrub-db >/dev/null 2>&1# Every day at 11:55pm EDT (due to conditional, commands only run during Daylight Saving Time (spring/summer)55 3 * * * [ `TZ=America/New_York date +\%Z` = EDT ] && php artisan scrub-db >/dev/null 2>&1Only one of the php artisan scrub-db commands will execute, depending on the time of year.
-
Automatically Put Files Into a YYYY/MM Directory Structure
123456789101112131415161718192021222324252627#!/usr/bin/env bash## This script will find .sql and .gz files in the current## directory and move them into YYYY/MM directories (created## automatically).BASE_DIR=$(pwd)## Find all .sql and .gz files in the current directoryfind "$BASE_DIR" -maxdepth 1 -type f -name "*.sql" -o -name "*.gz" |while IFS= read -r file; do## Get the file's modification yearyear=$(date -d "$(stat -c %y $file)" +%Y)## Get the file's modification monthmonth=$(date -d "$(stat -c %y $file)" +%m)## Create the YYYY/MM directories if they don't exist. The -p flag## makes 'mkdir' create the parent directories as needed so## you don't need to create $year explicitly.[[ ! -d "$BASE_DIR/$year/$month" ]] && mkdir -p "$BASE_DIR/$year/$month";## Move the filemv "$file" "$BASE_DIR/$year/$month"echo "$file" "$BASE_DIR/$year/$month"done -
Find and Open (in vim) Multiple Files
This is a quick set of examples for finding and opening multiple files in Vim.
1234567891011121314# Open all found files in vimdifffind . -name '.lando.yml' -exec vimdiff {} +# Open all found files, one-by-onefind . -name '.lando.yml' -exec vim {} \;# Open all found files in tabsfind . -name '.lando.yml' -exec vim -p {} +# Open all found files in vertical splitsfind . -name '.lando.yml' -exec vim -O {} +# Open all found files in horizontal splitsfind . -name '.lando.yml' -exec vim -o {} + -
Monitoring a Drupal 8 Migration Executed with Drush
Update 2 is proving to be the most useful method.
Update 1
Somehow I missed the documentation regarding the --feedback argument for the drush mi command. It’s similar to the methods below in that it helps you see that the migration is working, though you don’t see the totals. You can ask for feedback in seconds or items.

Update 2:
Another method that is a bit dirty but very useful is to add a single line to core/modules/migrate/src/MigrateExecutable.php.
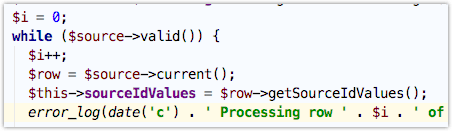
Adding the highlighted line to \Drupal\migrate\MigrateExecutable::import will let you see exactly where the migration is (which row is being processed).
If this is something you want permanently, consider posting an issue on d.o to request more verbose logging. This is my hackey solution for my immediate needs.
123456789$destination = $this->migration->getDestinationPlugin();while ($source->valid()) {$row = $source->current();$this->sourceIdValues = $row->getSourceIdValues();error_log(date('c') . ' Processing row ' . $this->counter . ' of ' . $this->migration->id() . ': ' . json_encode($this->sourceIdValues));try {$this->processRow($row);$save = TRUE;The output (in your logs, and in the drush output) will be something like this (institution_node is my migration, inst_guid is the only id):

As of Thursday, August 16, 2018 the counter() method is removed. So, you have to drop a counter variable in place like this:
This method of monitoring execution is surprisingly effective as it’s fast and you don’t have to lift a finger for it to happen each time you run a migration.
Original Post
This isn’t exactly an ideal solution, but it will do in a pinch. I’m working on a migration of more than 46,000 nodes (in a single migration among many). I needed a way to monitor the progress but I wanted to do it as quickly as possible (no coding). Here’s what I came up with, which I run in a new iTerm window.

All we’re doing is asking how many records are in the “member_node” migration map every 5 seconds. If we started at 6350 items we know that by the end of 20 seconds we have created 35 records.
We could also query the target content type itself:
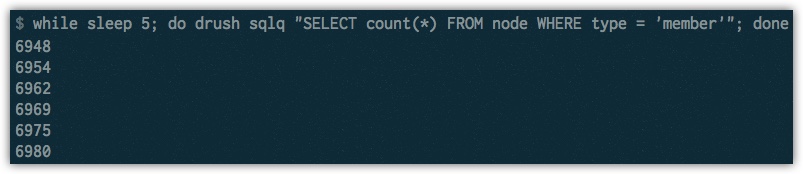
Here we can analyze the data the same way to see how many records the migration is creating.
I recognize that this is pretty crude, but it’s effective; you are able to see that it’s working, instead of just staring at an unchanging prompt and watching your CPU jump.
-
Recursively Finding and Operating on the Largest n Number of Files of a Particular Type
If you want to reverse-engineer this, you can work from left to right, adding one command at a time to see what each step does to the output.
1du -ah . | grep -v "/$" | sort -rh | grep "jpg" | head -25 | cut -f 2 | while read -r line ; do ls -alh "$line"; done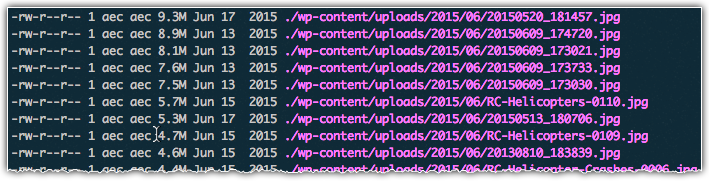
This example just lists the files we found, which is pointless given that’s what we already had before introducing the cut command.
How about a practical example?
Here’s how you can resize the 25 largest jpg files using mogrify (part of ImageMagick) to reduce the quality to 80:
1du -ah . | grep -v "/$" | sort -rh | grep "jpg" | head -25 | cut -f 2 | while read -r line ; do mogrify -quality 80 "$line"; done;What if you wanted to only grab files that are larger than a specific size? One way to do it is with the find command. For example, find all files greater than 8M:
1find . -type f -iname "*.jpg" -size +8M -exec du -ah {} \; | sort -rh | etc... -
Delete Last Command from Bash History
If you’re like me, on occasion you accidentally (or sometimes purposefully) include a password in a command. Until recently I would execute history , find the offending command’s number, then do a history -d NUMBER . It is kind of a pain.
The following deletes the last item in your bash history:
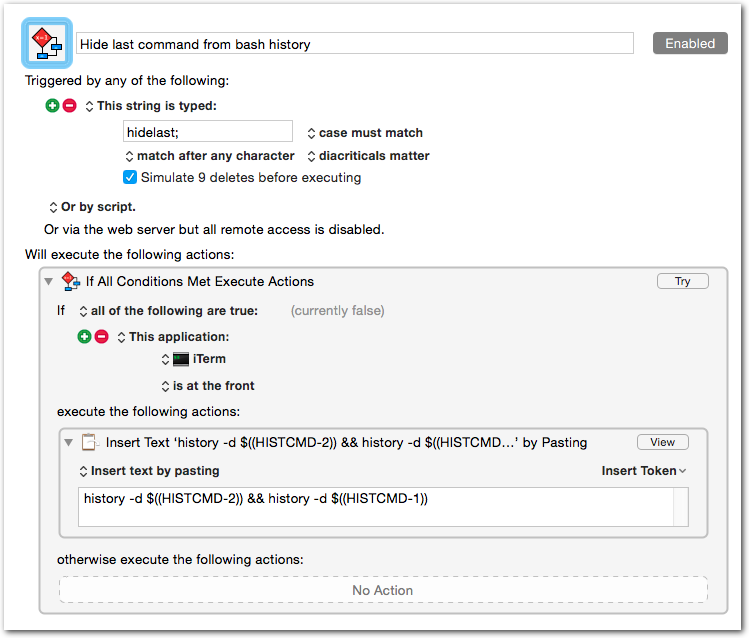
1history -d $((HISTCMD-2)) && history -d $((HISTCMD-1))You can create an alias for this, type it manually (umm, no thanks), or, as is the case for me, create a Keyboard Maestro macro for it. Here’s what my macro looks like:
-
Customizable Date variables in Keyboard Maestro
UPDATE: Though the solution below works well, I do recommend following the first commenter’s advice and using the ICUDateTime text tokens instead, which allow you to use any ICU date format, without having to invoke a shell script.
Sometimes you need a date and/or time variable in your Keyboard Maestro macros.
The easiestOne way I’ve found to do this is via an “Execute Shell Script” action. You’ll just use the date command and format as desired.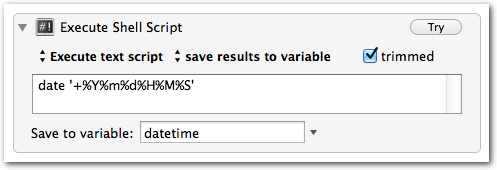
-
Determining Your Most Used Commands in Terminal
I’m always looking to automate things using Alfred, Keyboard Maestro, Text Expander, and Python. I was curious which terminal commands I use most often, so I did some experimenting. Basically I wanted to know how many times I’ve executed each unique command ( ssh myserverx or ssh myservery, not just ssh). I started by piping the output of history to sort (to group), then to uniq (to count), then back to sort (to sort by the number of occurrences).
Unfortunately, the result contained the same number of lines as the original history output. I figured this was because each line had a unique integer prefix (the line number in the history output). As it turns out, ~/.bash_history (where history gets its records) doesn’t contain line numbers. I simply changed the source and it worked like a charm:1history | sort | uniq -c | sort -n
1cat ~/.bash_history | sort | uniq -c | sort -n -
“755”-style permissions with ‘ls’
After a quick Google search for “ls permissions octal” I found a very handy alias to put in my .bashrc. Not only is it handy to see the OCTAL value of the permissions for each file/dir, it will undoubtedly help you more quickly recognize/interpret the normal ls -al output.
Example usage:1alias lso="ls -alG | awk '{k=0;for(i=0;i<=8;i++)k+=((substr(\$1,i+2,1)~/[rwx]/)*2^(8-i));if(k)printf(\" %0o \",k);print}'"
You can also type (or paste) this slightly different version into terminal:1234mycomp:~ adam$ lso755 drwxr-xr-x 15 adam staff 510 Dec 6 02:47 .vim644 -rw-r--r-- 1 adam staff 1136 Dec 18 16:55 .vim_mru_files600 -rw------- 1 adam staff 13665 Dec 18 16:56 .viminfo
1ls -l | awk '{k=0;for(i=0;i<=8;i++)k+=((substr($1,i+2,1)~/[rwx]/)*2^(8-i));if(k)printf("%0o ",k);print}' -
Automatically Stage All Deleted Files (Git)
Tab-completion is a really nice thing that we often take for granted. While working with Git I’ve found that it becomes inconvenient to stage (add for inclusion in the next commit) removed files using git rm path/to/my/file.php. Tab completion doesn’t work on paths that no longer exist, so you have to manually type the path to the deleted item. The following snippet automatically stages ALL removed files.
git ls-files -d -z | xargs -0 git rm --cached --quiet

{kind=link}